Optimize eDITH based on joint eDNA and direct sampling data
run_eDITH_optim_joint.RdFunction that performs search of optimal parameters of an eDITH model fitted on both eDNA and direct sampling data.
Usage
run_eDITH_optim_joint(data, river, covariates = NULL, Z.normalize = TRUE,
use.AEM = FALSE, n.AEM = NULL, par.AEM = NULL,
no.det = FALSE, ll.type = "norm", source.area = "AG",
likelihood = NULL, sampler = NULL, n.attempts = 100,
n.restarts = round(n.attempts/10), par.optim = NULL,
tau.prior = list(spec="lnorm",a=0,b=Inf, meanlog=log(5),
sd=sqrt(log(5)-log(4))),
log_p0.prior = list(spec="unif",min=-20, max=0),
beta.prior = list(spec="norm",sd=1),
sigma.prior = list(spec="unif",min=0,
max=1*max(c(1e-6, data$values[data$type=="e"]),
na.rm = TRUE)),
omega.prior = list(spec="unif",min=1,
max=10*max(c(0.11, data$values[data$type=="e"]),
na.rm = TRUE)),
Cstar.prior = list(spec="unif",min=0,
max=1*max(c(1e-6, data$values[data$type=="e"]),
na.rm = TRUE)),
omega_d.prior = list(spec="unif",min=1,
max=10*max(c(0.11, data$values[data$type=="d"]),
na.rm = TRUE)),
alpha.prior = list(spec="unif", min=0, max=1e6),
verbose = FALSE)Arguments
- data
eDNA and direct observation data. Data frame containing columns
ID(index of the AG node/reach where the sample was taken),values(value of the eDNA or direct measurement) andtype(equal to"e"for eDNA data and to"d"for direct observation data). eDNA values are expressed as concentration or number of reads; direct observations are expressed as numbers of individuals.- river
A
riverobject generated viaaggregate_river.- covariates
Data frame containing covariate values for all
riverreaches. IfNULL(default option), production rates are estimated via AEMs.- Z.normalize
Logical. Should covariates be Z-normalized?
- use.AEM
Logical. Should eigenvectors based on AEMs be used as covariates? If
covariates = NULL, it is set toTRUE. IfTRUEandcovariatesare provided, AEM eigenvectors are appended to thecovariatesdata frame.- n.AEM
Number of AEM eigenvectors (sorted by the decreasing respective eigenvalue) to be used as covariates. If
par.AEM$moranI = TRUE, this parameter is not used. Instead, the eigenvectors with significantly positive spatial autocorrelation are used as AEM covariates.- par.AEM
List of additional parameters that are passed to
river_to_AEMfor calculation of AEMs. In particular,par.AEM$moranI = TRUEimposes the use of AEM covariates with significantly positive spatial autocorrelation based on Moran's I statistic.- no.det
Logical. Should a probability of non-detection be included in the model?
- ll.type
Character. String defining the error distribution used in the log-likelihood formulation. Allowed values are
norm(for normal distribution),lnorm(for lognormal distribution),nbinom(for negative binomial distribution) andgeom(for geometric distribution). The two latter choices are suited when eDNA data are expressed as read numbers, whilenormandlnormare better suited to eDNA concentrations.- source.area
Defines the extent of the source area of a node. Possible values are
"AG"(if the source area is the reach surface, i.e. length*width),"SC"(if the source area is the subcatchment area), or, alternatively, a vector with lengthriver$AG$nodes.- likelihood
Likelihood function. If not specified, it is generated based on arguments
no.detandll.type.- sampler
Function generating sets of initial parameter values for the optimization algorithm. If
NULL, initial parameter values are drawn from the default prior distributions ofrun_eDITH_BT. See details.- n.attempts
Number of times the optimizing function
optimis executed. Every time a "restart" happens (seen.restarts),sampleris used to draw an initial parameter set. If a "restart" does not happen, the optimal parameter set from the previous attempt is used as initial parameter set.- n.restarts
Number of times a random parameter set is drawn as initial condition for
optim.- par.optim
List of parameters to be passed to
optim. By default, the likelihood is maximized (i.e.,control$fnscale = -1), and the maximum number of iterations is set to 1e6. The default optimization method is "Nelder-Mead" (same default as inoptim).- tau.prior, log_p0.prior,beta.prior,sigma.prior,omega.prior,Cstar.prior
Prior distribution for the relevant parameters of the eDITH model.
- omega_d.prior
Prior distribution for the overdispersion parameter for direct sampling density observations.
- alpha.prior
Prior distribution for the inverse DNA shedding rate (i.e., the organismal density that sheds a unit eDNA value per unit time).
- verbose
Logical. Should console output be displayed?
Details
This function attempts to maximize the log-posterior (sum of log-likelihood and log-prior) via the
non-linear optimization function optim.
If specified by the user, sampler must be a function that produces as output a "named num"
vector of parameters. Parameter names must be same as in the likelihood. See example.
By default, AEMs are computed without attributing weights to the edges of the river network.
Use e.g. par.AEM = list(weight = "gravity") to attribute weights.
Value
A list with objects:
- p
Vector of best-fit eDNA production rates corresponding to the optimum parameter estimates
param. It has length equal toriver$AG$nNodes.- C
Vector of best-fit eDNA values (in the same unit as
data$values, i.e. concentrations or read numbers) corresponding to the optimum parameter estimatesparam. It has length equal toriver$AG$nNodes.- probDet
Vector of best-fit detection probabilities corresponding to the optimum parameter estimate
param_map. It has length equal toriver$AG$nNodes. If a customlikelihoodis provided, this is a vector of null length (in which case the user should calculate the probability of detection independently, based on the chosen likelihood).- param
Vector of named parameters corresponding to the best-fit estimate.
- covariates
Data frame containing input covariate values (possibly Z-normalized).
- source.area
Vector of source area values.
- out_optim
List as provided by
optim. Only the result of the call tooptim(out ofn.attempts) yielding the highest likelihood is exported.- attempts.stats
List containing relevant output for the different optimization attempts. It contains
lp(vector of maximized log-posterior values for each single attempt),counts(total function evaluations),conv(convergence flags as produced byoptim), andtau(best-fit decay time values in h).
Moreover, arguments ll.type (possibly changed to "custom" if a custom likelihood is specified), no.det
and data are added to the list.
Examples
data(wigger)
data(dataCD)
## fit eDNA concentration and direct observation data - use AEMs as covariates
set.seed(9)
out <- run_eDITH_optim_joint(dataCD, wigger, n.AEM = 10,
n.attempts = 1) # reduced n.AEM, n.attempts for illustrative purposes
# it is recommended to attempt optimization several times to ensure convergence
# \donttest{
library(rivnet)
# best-fit map of eDNA production rates
plot(wigger, out$p)
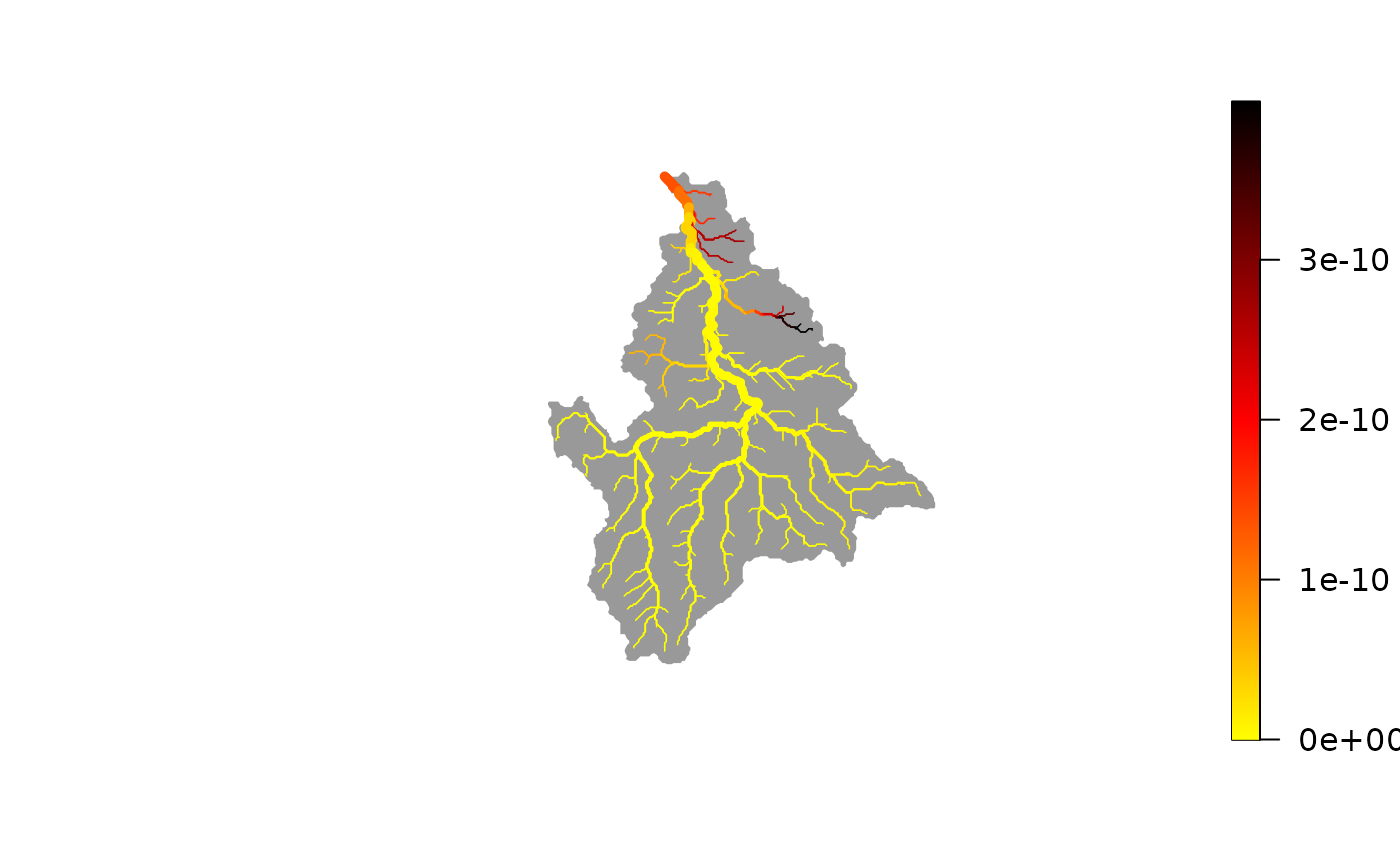 # best-fit map of detection probability
plot(wigger, out$probDet)
# best-fit map of detection probability
plot(wigger, out$probDet)
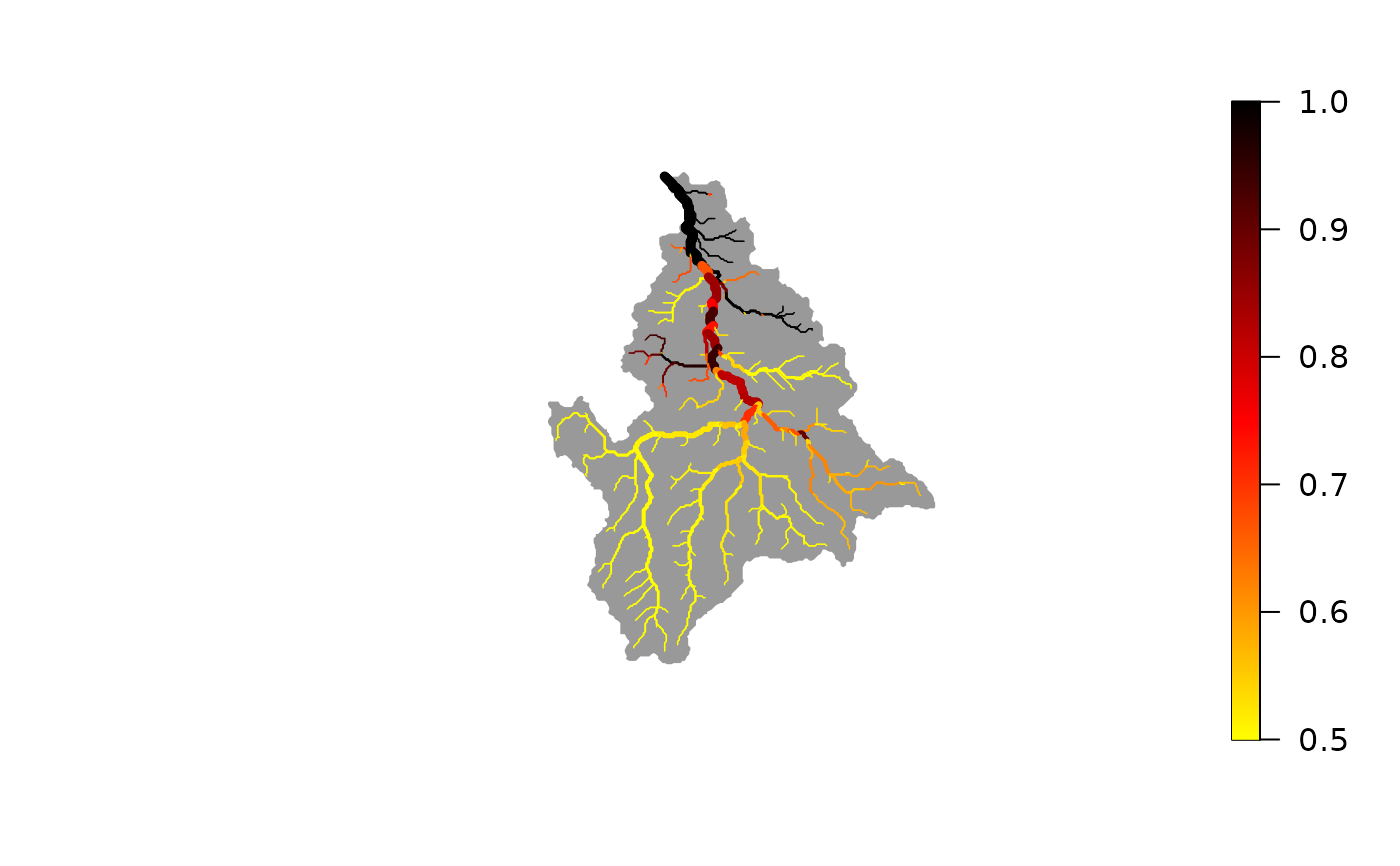 # compare best-fit vs observed values
data.e <- which(dataCD$type=="e")
data.d <- which(dataCD$type=="d")
plot(out$C[dataCD$ID[data.e]], dataCD$values[data.e],
xlab="Modelled (MAP) eDNA concentrations", ylab="Observed eDNA concentrations")
abline(a=0, b=1)
# compare best-fit vs observed values
data.e <- which(dataCD$type=="e")
data.d <- which(dataCD$type=="d")
plot(out$C[dataCD$ID[data.e]], dataCD$values[data.e],
xlab="Modelled (MAP) eDNA concentrations", ylab="Observed eDNA concentrations")
abline(a=0, b=1)
 plot(out$p[dataCD$ID[data.d]], dataCD$values[data.d],
xlab="Modelled (MAP) eDNA production rate", ylab="Observed density data")
plot(out$p[dataCD$ID[data.d]], dataCD$values[data.d],
xlab="Modelled (MAP) eDNA production rate", ylab="Observed density data")
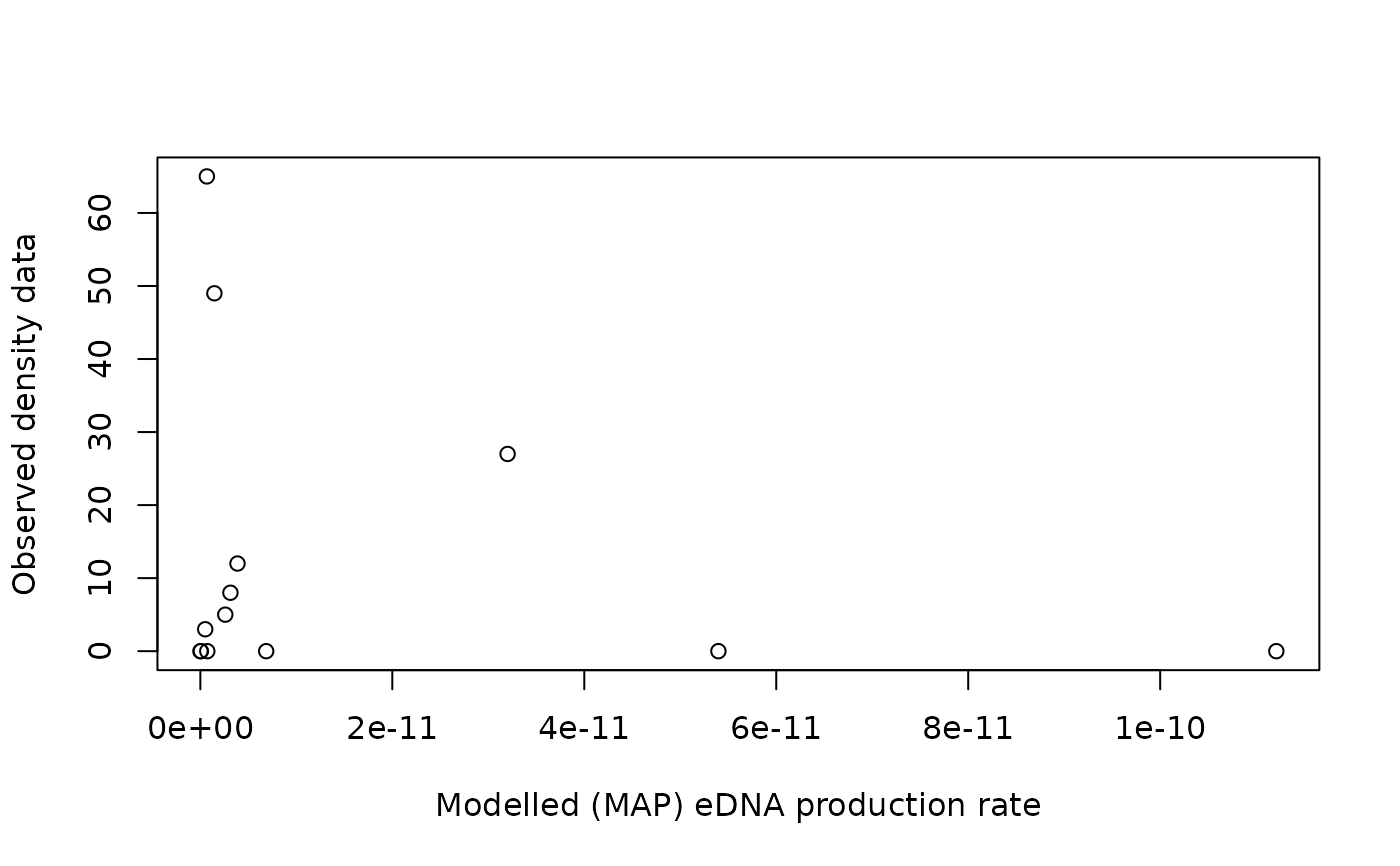 # }
# }